딥러닝의 헬로 월드 예제라고 할 수 있는 MNIST 데이터를 CNN 으로 분석하는 방법에 대하여 알아보는 글을 작성해 보고자 합니다. 이 글은 딥러닝이 무엇인지 기본적인 내용을 알고 있는 분을 대상으로 작성하였으므로 딥러닝이란 무엇이며, 텐서플로란 무엇이며, 케라스는 또 무엇인지에 대한 내용을 생략하도록 하고 바로 시작하겠습니다.

[이 CNN 이 아닙니다...]
1. 데이터 전처리
MNIST 데이터는 케라스를 이용할 경우 매우 간단히 불러 올 수 있습니다.
불러온 이미지 데이터를 X 라 하고 0 ~ 9 까지 붙인 이름표를 Y 라고 명명하도록 하겠습니다. 데이터를 불러와 보면 70,000 개의 데이터가 있습니다. 케라스에서는 이미 70,000개의 데이터 중 불러온 데이터 중 60,000개를 학습 데이터로, 그리고 나머지 10,000개를 테스트 데이터로 사용하도록 설정 되어 있습니다.
각각의 데이터는 28 x 28 이미지로 총 784개의 속성을 가지고 있는 2차원 배열 입니다. 학습을 위해 데이터를 784개의 1차원 배열로 바꿔주어야 합니다.
이 글을 읽으시는 분들은 이미 아시겠지만, MNIST 의 각각의 데이터는 0 ~ 255 사이의 값으로 이뤄진 흑백의 손글씨 이미지 입니다. 0 ~ 255 사이의 값을 그대로 사용해도 되지만 모델의 성능을 위해 0 ~ 1 사이의 값으로 변환 하는 과정을 거치면 좋습니다. 이처럼 데이터의 분산이 클 때 분산의 정도를 바꿔주는 과정을 데이터 정규화 (Normalization) 이라고 합니다. 1차원 배열로의 변환 및 정규화 과정을 학습 데이터와 테스트 데이터 모두에 적용 합니다.
MNIST 데이터를 이용하여 우리가 궁극적으로 하고자 하는 바는 0 ~ 255 사이의 값으로 이뤄진 원본 데이터를 보고, 이 데이터가 0 ~ 9 사이의 숫자 중 어떤 것인지 예측하는 것 입니다. 딥러닝의 분류 문제로 이를 위해서는 원-핫 인코딩 방식을 적용 해야 합니다. 즉, 0 ~ 9까지의 정수 값을 갖는 형태가 아닌 0 이나 1로 이뤄진 벡터로 수정해야 합니다. 만약에 '3' 이라는 숫자라면 3을 [0, 0, 1, 0, 0, 0, 0, 0, 0] 로 바꿔주어야 한다는 것 입니다. 원-핫 인코딩 변환을 위해 케라스의 np_utils 의 to_categorical() 함수를 사용 합니다.
2. 일반적인 딥러닝 모델링
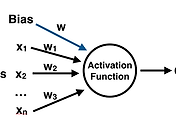
데이터 전처리가 끝나면 이제 데이터 모델링을 해보겠습니다. 성능의 비교를 위해 CNN 으로 바로 들어가기에 앞서 일반적인 딥러닝 모델을 먼저 살펴 보겠습니다. 케라스를 사용해 프레임을 만들어 줍니다.
입력 값은 784 개, 은닉층은 512개의 노드가 있으며 출력은 10개인 모델로 은늑층과 출력층의 활성함수는 각각 relu 와 softmax 를 사용하였습니다. 분류 문제 이므로 오차 함수는 categorical_crossentropy, 최적화 함수는 adam 을 사용하겠습니다.
모델을 실행 할 때, 최적화 단계에서 일정 횟수 이상 반복해도 모델의 성과 향상이 없을 경우 모델을 중단하도록 설정해 주는 것이 좋습니다. 여담으로 저 같은 경우 처음 딥러닝 강의를 들을 때 부팅 되는 것도 힘겨워하던 제 구형 노트북에서 모델을 돌린 적이 있는데 종종 자기 전에 모델 돌려두고 자고 일어나서 출근 하기 전까지 돌아가고 있는 모습을 자주 보곤 했었습니다. 그런데 오히려 오차가 증가하거나 의미 없이 돌아가고 있는 것이였다면 눈에서 습기가...
마지막으로 데이터를 200개씩 각각 30번 실행하게끔 설정하고, 테스트 데이터를 최종 모델의 성과 측정에 사용할 수 있도록 합니다.

1개의 은닉층을 가지는 기본 딥러닝 모델에 대한 결과를 그래프로 출력해 보면 위와 같은 모습을 볼 수 있습니다. 10번째 epoch 일 때 최적의 결과가 나오고, 이후 10번 더, 즉 20번째 실행까지 시도했을 때 오차(loss)가 더 줄어들지 않자 종료가 되었습니다. 테스트 데이터와 달리 학습 데이터의 오차는 계속해서 줄어들고 있는 것으로 볼 때 과적합(overfitting) 이 일어나기 전에 학습이 무사히 끝난 것으로 보입니다.
이정도만 해도 훌륭한 정확도를 보입니다. 하지만 이러한 기본 모델에 추가적인 층을 더하고, 옵션을 더한다면 더 좋은 성능을 얻을 수 있습니다. 이제 다 된 딥러닝 모델에 컨볼루션을 뿌려 보겠습다.
3. CNN
3.1. Convolution
CNN (Convolutional Neural Network) 는 입력된 이미지에서 다시 한번 특징들을 추출하는 마스크(혹은 필터, 혹은 윈도, 혹은 커널) 를 추가하는 방법 입니다.

그림으로 이해하면 조금 쉽습니다. x 라는 원본 이미지에 h 라는 마스크를 준비 합니다. h 라는 마스크의 각 칸에는 가중치가 드러 있습니다. 그림에서 h(-1, -1) ~ h(1, 1) 이 각각의 가중치 입니다. 이 가중치들은 원본 이미지 x 에 원래 있던 값과 곱해져서 새로 추출된 값이 나옵니다.
즉, h(-1, -1)*x(m-1, n-1) + .... + h(0, 0)*x(m, n) + ...... + h(1, 1)*x(m+1, n+1) = y(m, n) 이라는 새로운 값이 나오고, 이렇게 나온 값들이 모인 새로운 y 층을 우리는 컨볼루션(합성곱) 이라고 부릅니다. 이러한 마스크를 여러 개 만들 경우 여러 개의 컨볼루션이 나오게 되겠죠.
케라스를 사용하면 손쉽게 컨볼루션 층을 추가할 수 있습니다. Conv2D 를 사용하면 되는데 파라미터로 대개 마스크의 갯수, 마스크(커널) 사이즈 그리고 입력 되는 값을 전달해야 합니다. MNIST 의 경우 28 x 28 의 흑백의 이미지 이므로 (28, 28, 1) 을 전달 합니다. 마지막으로 해당 층의 활성 함수를 정의 합니다. 이러한 방식으로 컨볼루션 층을 2개 추가해 보겠습니다.
3.2. Max pooling

그림과 같이 원본 이미지를 네개의 구역으로 나누고, 2 x 2 의 맥스 풀링을 적용하면 각각의 구역에서 가장 큰 값인 20, 30, 112, 37을 가지고 새로운 층을 만들어 낼 수 있습니다. 맥스 풀링도 케라스를 사용할 경우 간단하게 모델에 추가할 수 있습니다.
3.3. Drop out 과 Flatten
컨볼루션, 맥스 풀링, 드롭 아웃과 플랫튼까지 적용하고 나면 최종적인 CNN 의 딥러닝 모델링의 모습은 아래와 같다고 볼 수 있을 것 같습니다.
[input] ----> [convolution | relu] ----> [convolution | relu] ----> [max pooling] ----> [drop out] ----> [flatten] ---> [hidden layer | relu] ---> [drop out] ---> [output | softmax]
optimizer = adam

최종적인 모델링을 실행 시킨 결과는 아래와 같습니다. 최종 결과는 99.28% 였습니다. 데이터 안에 사실상 사람의 눈으로도 구분하기 어려운 글씨들도 있다는 것을 감안했을 때 CNN 으로 거의 대부분의 글씨를 맞출 수 있다는 것을 볼 수 있었습니다.
'DL' 카테고리의 다른 글
| 시작하는 이들을 위한 코세라와 유다시티 딥러닝 유료 강의 비교 (5) | 2017.09.14 |
|---|---|
| [DL 101] scikit learn 으로 만들어 보는 인공신경망 (0) | 2017.08.23 |